Liste der Chromosomen » Chromosom 5
Wo bist Du, Gen?
Das menschliche Genom
Jedes Chromosom kann mit einem Knäuel verglichen werden, dessen Faden die DNA ist. Die DNA setzt sich aus einer einfachen Abfolge von vier verschiedenen Molekülen zusammen: Adenin, Thymin, Cytosin und Guanin oder A, T, C und G. Die gesamte DNA unserer 23 Chromosomen wurde sequenziert. Das Ergebnis? Ein Text von mehr als 3’000’000’000 A, T, C und Gs, den wir das menschliche Genom nennen.

Ein Stück der DNA-Sequenz
Ein Gen?
In diesem Text aus 3 Milliarden Zeichen verbergen sich unsere Gene. Ein Gen ist ein Stück DNA von variabler Länge. Man hat etwa 20’000 Gene entdeckt, die die Grundlage für sämtliche Proteine in unserem Körper bilden.
Aber wie können wir diese Gene finden, lesen und verstehen?
vom Gen zum Protein
Alle Gene haben einen Anfang und ein Ende. Dazwischen liegt ein Rezept, zum Beispiel für die Herstellung eines Proteins. Ein Protein ist eine Abfolge von Molekülen, die man Aminosäuren nennt. Von diesen gibt es 20 verschiedene, die jeweils mit einem Buchstaben benannt werden. Vom Gen zum Protein gelangt man wie vom Chinesischen ins Russische: Man benötigt einen Übersetzer. Oder besser gesagt: Man braucht den genetischen Code.

|
ein Code für alle
Der genetische Code ist überraschend einfach.
Drei aufeinanderfolgende „Buchstaben“ in der DNA entsprechen einer Aminosäure in einem Protein. Indem man die ‚Dreibuchstabenworte‘ der DNA liest, übersetzt man nach und nach die DNA-Sequenz in eine Proteinsequenz. Genau so produzieren unsere Zellen Proteine. Der genetische Code ist zudem fast in allen Organismen gleich: von Viren über Bakterien, Schnecken, Tulpen, Schlangen und Menschen bis hin zum Elefanten.

Übersetzung eines Stückes einer DNA-Sequenz in ein Stück Proteinsequenz mithilfe des genetischen Codes |
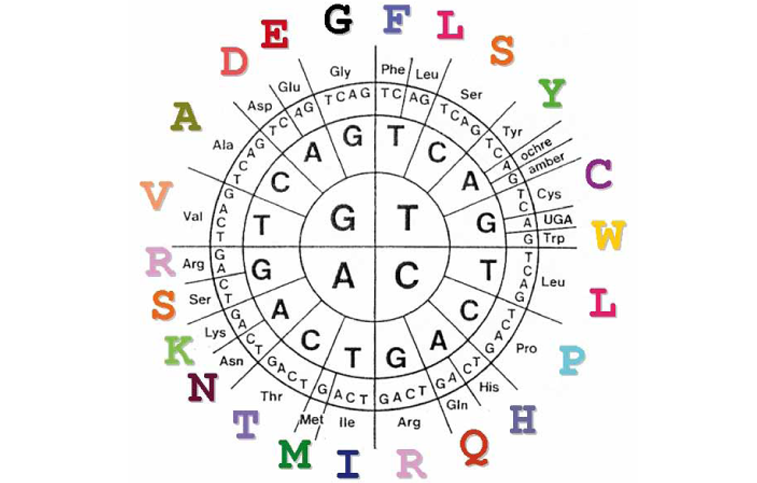
der genetische Code
Hier ist eine von vielen Möglichkeiten, den genetischen Code darzustellen.
Zum Lesen startet man im Zentrum und bewegt sich nach außen.
Beispiele: ATG (auf der DNA) kodiert für die Aminosäure M (Methionin) und TTC kodiert für die Aminosäure F (Phenylalanin).
TAA, TAG und TGA kodieren nicht für eine Aminosäure, sondern signalisieren ‚Stop‘.
Eine Nadel im Heuhaufen!
Die Natur ist nicht einfach! Die Gene, die für Proteine kodieren, stellen nur 5 % unserer DNA dar. Sie zu finden ist wie die Suche nach der Nadel im Heuhaufen! Zudem sind die Gene nicht nur überall in der DNA verstreut, sie sind auch häufig unterbrochen. Die Wissenschaftler müssen die einzelnen Teile suchen und zusammenfügen, damit das Gen richtig abgelesen werden kann.
Gene vorhersagen
Genau für dieses Problem wurden Computerprogramme geschrieben, die den Anfang, das Ende und die dazwischenliegenden Teile eines Gens vorhersagen können. Solche Programme sind zwar noch weit davon entfernt, perfekte Ergebnisse zu liefern, sind aber trotzdem eine wertvolle Hilfe für die Biologen.
Externe Links
Bioinformatik – Experte:
Übersetzen Sie die Sequenz ‚tgtgagcgagttgagcttgccact‘ mithilfe des Programms „Translate“ (Wählen Sie die Option Output format: Compact („M“, „-„, no space))
Bioinformatik – Experte: Die Struktur des Gens DROSHA in der Datenbank Ensembl
Corresponding protein in UniProtKB/Swiss-Prot
Bioinformatik – Experte: Eine Liste aller Gene auf Chromosom 5